Security and Human Behavior 2026 Day 1

Welcome to the 19th Security and Human Behavior. The write-up below is a live-blog of the workshop. The below summaries are my interpretation and should not be seen as a litteral quotes from the presenters.
Contents:
- Session 1: Abuse and wickedness
- Burcu Bulgurcu, Sarah Chun, Miranda Wei, Marie Vasek, Stuart Schechter, Ali Ahmed
- Session 2: AI
- Speakers: Sameer Patil, Laura Brandimarte, Judith Donath, James Mickens, Bruce Schneier, Arun Vishwanath
- Session 3: Privacy
- Speakers: Emilee Rader, Maschio Fernando, Tesary Lin, Florian Schaub, Christina Fong, Melissa Hathaway
- Session 4: Individual Security Behaviors
- Speakers: Richard John, Norman Sadeh, Nathan Malkin, Kent Seamons, John D’Arcy, Rick Wash]
Also see:
Sesson 1: Abuse and Wickedness
Burcu Bulgurcu, Sarah Chun, Miranda Wei, Marie Vasek, Stuart Schechter, Ali Ahmed
Burcu Bulgurcu
Deepfake related phishing and fake doctored images/videos used for persuasion. These types of attacks are very effective. The discussion in this space is shifting from accuracy. Trust is becoming more important including trust of sources. Research study finding a surprising number of participants (students) deceived by deepfakes.
The line between strong persuasion and deception is hard to differentiate sometime. Need to study this more. Disclaimers have promise, but how might they look in different situations is an ongoing challenge.
Sarah Chun
Removing Child Sexual Abuse Materials from online media companies. Or: “Looking for what you never want to find.”
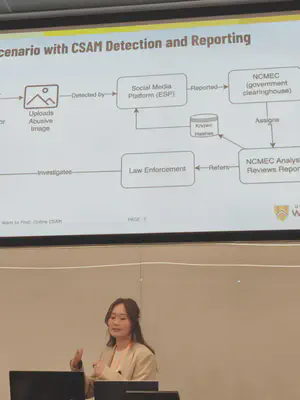
The amount of child sexual abuse material online is truly staggering and terrible. Sarah is working on a project to better understand the dynamics of the space, how social media companies are interacting with non-government agencies like NECMEC. These interactions cause frictions that lead to less identification of this content then might normally exist.
Four main tensions:
- Legal
- In US this content must be reported the moment that media companies become aware of the content.
- Challenge in balancing removing content and possibly blocking good users
- Automation
- Automation is great, but once turned on you cannot unsee what was found. Remember the law is around awareness running automation makes groups aware.
- Data Accuracy
- The data is less accurate than might be expected.
- Human costs
- Viewing of this content by moderators is costly in terms of mental health.
Miranda Wei
Title: Harm is not an anomaly nor a reason to despair.
Research on IBSA: Image-based sexual abuse
Its easy to think of IBSA as an anomaly. That is rare, not something most people experience. And that most people need specialized help.
Studies found that most people need general advice. Also most of the perpetrators are people to victims know. Also there is a mix of severity of harms.
It matters that these harms are not an anomaly because if it is rare we handle it one way, but if it is a common event then we might need to do more society-level interventions.
Harm is a reason to despair…. “your research is depressing”. But the real issue is general despair “how can computer scientists even do something here” or “bad things have always happened”.
The worst outcome is to give up. Our role as scientists is to solve hard problems.
There is no such thing as perfect security, there is only threat modeling. Threat modeling is one of the most appliciable approaches in the situation of ISBA. It accepts that perfect security may not happen, but security can be improved. Frictions can be added to reduce issues.
Combating AI-enabled sexual abuse material. Addressing this space is quite challenging. AI makes it super easy to generate CSAM, and it means that hash matching does not work. It is very hard for well meaning organizations to build solutions when having this content is highly illegal. CSAM laws are inhibiting progress on building some types of solutions. Researchers also cannot test these systems again because the content is highly illegal. A possible solution is to consider building an IBSA or CSAM safe harbor for researchers.
Marie Vasek
Title: Interaction Scams
Analyzed over 1.3 million text messages in the UK that had been reported.
- 186k spam
- overwhelmingly gambling messages
- Do contain links
- 213k scams
- Uncommon to include links
- Lots of interactive scams that clearly trying to cause another action like texting back, calling a number
But how do we know that these are scams/spam?
- Tried responding to a good number of messages. Particularly “hi mom, I dropped my phone”
Most pig butchering sams were a “female” scammer targeting a “male” victim.
Stuart Schechter
Title: Cultural norms
South Korea - Stuart was there for 5 years.
- Resume’s in South Korea includes the image of the person, they tried to stop this, but now you cannot ask someone’s weight.
Privacy around sexual identity and how relationships are managed is an interesting topic. Such privacy is negotiated as a group because a statement by one partner impacts the privacy of the other partner, and possibly the whole family.
Books:
- Different: Gender through the eyes of a primatologist by Frans de Waal
Ali Ahmed
Bug bounty programs exist so that people can report bugs to organizations and also get compensated. The goal here is to get bugs fixed, possibly cheaply. The question is: is this an effective approach? Does it increase the number of attacks on a system? Organizations tend to be very secretive about the number of attacks they get.
In 2020 CISA ordered every federal agency to have a vulderability disclosure program. This is an opportunity for study, a natural experiment.
Through FOIA request Ali got incident reports. Turning on VDP on average increased attacks on the web by 24%. But impact on other types of incidents like improper usage is minimal to none.
Good hackers need attention to have a Vunerability Reporting System have a positive effect. Attention here means things like getting the reported bugs fixed.
Q&A
- Work on CSAM by Sarah and Miranda - you are awesome for doing work in this space.
- Tatiana Ringernberger does some interesting work in this space.
- Laura Draper from Stanford did a excellent report on not only CSAM but also on child exploitation
- To Ali Ahmed - Have you also studied Hacker 1 because you can get paid in blockchain - so it is possible for employees to submit and companies to not know.
- Actually submission by employees is generally allowed, just not the security team.
Session 2: AI
Speakers: Sameer Patil, Laura Brandimarte, Judith Donath, James Mickens, Bruce Schneier, Arun Vishwanath
Sameer Patil
Universities who are using Duo for two factor authentication: most of the audience is from a University that is using Duo.
Do people think the user experience of two factor authentication, such as Duo, to be easy? Most of the audience has hands down.
Starting to study the usability of two factor authentication in Universities. Have been collecting configurations of Duo security accross many Universities across the US. Some let you stay logged in for 1 day and some for more than a month. There is also quite a range of options for how two factor can be done including SMS push, codes, and app.
The intersting part here is around incentivisations. How are Universities incetivised to setup these types of tools?
A priority at Universities is starting to be cyber insurance. To get cheaper insurance there are a pile of requirements like turning on two factor authentication. The question is who takes the liability. How do we address these pressures. Human factors do not seem to be taken into account well. Universities are also just different structurally. A corperate laptop is different from a Professor laptop that might have sensitive data protected under ethics rules.
The yellow banner of “you are emailing someone outside your University” is an example. The banner is wrong in several cases, like emails from subdomains. How do we bring the user experience back in?
Laura Brandimarte
Title: When suspicion Fails: Understanding and preventing financial fraud against older adults
Trying to establish why the elderly fall for scams like tech support scams. Collected data from elderly facilities: interviews about all kinds of fraud the eldery suffer from.
64% raised suspicion during the encounter, 41% of suspicious victims still lost money. When no suspicion at all, then ~80% fall victim. A participant that had an issue, used Google to find help, and called the phone number they found: “I kept telling myself, this is Apple. This dooes not feel right, but this is Apple support.”
Most recommendations are based on a premis that if people were aware, that would fix the problem. But our data shows that in about 50% of cases, awareness is not enough.
Why do people who are suspicious not act on those suspicions.
- Socioemotional Selectivity - Older adults pritorize emotinal meaning over information
- Routine Activity Theory - Capable guardians prevent exploitation
- Persuasion Research - Authority, urgency, commitment escalation drive compliance
Created Suspicion-override model with four pathways:
- Trust Anchoring
- Goal-State Momentum
- Adversarial Counter-response
- Guardian Abscence
Judith Donath
Title: Provable images
Fake images are a thing and a big problem that can impact global issues. The other issue is that real images are now under suspicion. So both problems are real: real images are no longer persuasive, and fake images can look real.
Judith works on Signaling Theory.
Long ago photographs of ghosts were very possible. Its one of the things that made photography popular. But in mondern terms these would be fake images.
No one is good at identifying fake images. AI generators are improving faster than the AI detectors. The real issue is that we need to know before showing people if an image is or is not fake.
Idea: lets get a camera to cryptographically sign photos it takes. If it does on-camrea modifications, then it can sign what they were. Assuming that works correctly: it would help professional photographers that want to prove that they took it.
But what does the technology solve:
- Image that is taken in a diffefrent place or context than what claimed
- Low demand for the truth - sometimes we don’t care if it is fake or not
That still leaves a big space of people who would rather not be sending out or forwarding fake images. This is a usability problem. How do we tell people that an image is or is not true. Want to avoid saying that other images are “fake”. Because “fake” may be intentionally a form of communication that has a real message even if the image itself is created rather than the initial literal photograph.
We need to start thinking about
James Mickens
AI, AI, AI, everywhere.
“Who wouldn’t want all our interactions to be mediated by a large number of floating point numbers.”
The computer scientist, legal, and policy groups need to start talking about AI. Models are increasingly connected to societally inportant infrastructure. The military is adopting it. Models are also increasingly complex. Models are also perfectly fine with lieing. Models will try and engage in self preservation.
“This is not good.”
What about AI safty research? Many models lack secure mechanisms for inference-time enforcement. Where is the trusted hardware and software that will enforce these policies.
How do we protect the software and hardware that monitor and protect us from the models.
Guillotine is a Hypervisor for Potentially Malicious AI. Building control infrastructure to deal with AI-specific threats.
But we need to link these protections to the law. The problem is that solutions like Guillotine do slow the models down, even if it is by a very small amount. So without some pressure building them is not a priority.
We need the hypervisor CPUs to be able to inspect the model, but not the other way around.
Bruce Schneier
Title: Cybersecurity in a World of Instant Software
Anthropic announced Claud Mythos Preview - so wonderful, magical, that it cannot be released to the general public. Pure marketing genious. Press happily repeating piles of unverified claims about how wonderful this model is. No information on things like false positives. One of the reasons they haven’t released the model is how expensive it is to run, they just don’t have enough compute.
OpenAI shortly later: our model is so awesome we are not going to release it either.
There is some reality here: Mozilla uses Mytos to find many flaws in the browser. Similarly Apple patched a serious vulnerability found by AI. Other groups have worked to reproduce Mythos’ results using a much cheaper model.
How do we handle the huge number of vulnerabilities that will be found.
The main topic though is how are we going to handle the age of Instant Software. Software is getting cheaper to write. AI writes code it uses, then just throws away. Some software is just instantly created, used and removed. But other instant software sticks around.
Discovery of vulnerabilities is becoming easy. The newer fancy models are not necessarily better, they are better in that less complex prompts are needed to do it.
Open source software is the most vulnerable here. Simlarly libraries that are being pulled into propriotoriy software.
Unknowns:
- AI will transform what a vulnerability researcher does.
- How good will it become? Right now finding is easier for an AI than finding and patching. If it can do both the situation changes drastically. There is a world where finding and fixing vulns becomes part of the normal software development process.
- Patching itself. Private individuals should turn on patching. But large organizations do not turn on auto patching, because of the risks.
- How good are AI at finding obscure vulnerabilities? We are starting to see AI chaining vulnerabilities. You can imagine a self-healing system where an AI is finding and patching systems in real time.
- Are these AIs trustworthy? The attacker is not going away. The attacker’s new goal is to hack the AI so that it does not find the vulnerability.
Arun Vishwanath
Title: A Paradign for Preserving Human Interrupt Capacity in Automation-Rich AI Systems: A Suspicion Reflex Framework
My group has worked on how people think about scams, why they fall for them, lots of understanding of people. At some point decided to switch to influencing policy. Then realized that policy makers don’t understand how policy is implemented at companies. There are many people doing nothing but trying to implement the policies that are being created by multiple nations.
What is really going on at organizations?
Common Threads
- Synthetic News Amplification
- Automation Bias
- Fake ransom calls
- AI hallucination acceptance
- Deepfake executive request
Came up with the Suspicion Reflex Theory (SRT) model as a state. What is it that doesn’t cause suspicion? Is there a framework for how we design technology. We have temporal constraints. Constraints around congnition. Perceptual similarity.
People have mental “scripts” that they run.
- Stage 1: automation layer
- Stage 2: Anomaly Detectoin
- Stage 3: suspicion reflex (interrupt)
Bypasses happen. For example a scrpit opperating in your mind before you run any type of meaningful detection.
Fluency - humans are good at short-cutting cognitive tasks. Drive a long distance, and try to remember the trip.
We need Anti-Fluency: nonlinear tradefoff between efficiency/fluency and oversign/safety. Systems should not optimize seamlessness beyond the threshold where human interruption collapses.
Session 3: Privacy
Speakers: Emilee Rader, Maschio Fernando, Tesary Lin, Florian Schaub, Christina Fong, Melissa Hathaway
Emilee Rader (The Information School, UW-Madison)
Privacy policie spromise anonymity….
People believe that anonymity protects them. Yet they do things like making a new account and then share identifying information.
What do people think anonymity is?
Survey with 291 survey respondents on Prolific. Elicitated descriptions of “online or offline situation in the past where you felt anonymous or where you were trying to be anonymous”. Two of the close ended questions:
- Motivations
- Answers matched the existing literature. Many people feeling safe from retalitation or unwanted attention. Avoiding being tracked or profiled. Sharing true thoughts, feelings, or opinions.
- The motivations are all very different, even the most common ones.
- Approaches
- Trying to be unidentifyable (79%), trying to be unreachable or untraceable (68%)
- Less common answers are interesting: trying to be indistinguishable from others (51%)
Some participants are trying to do things like not overshare with people they know (questions on forums about potty training) and wanting to not be bothered (seating in a restarant in a low-visibility area).
Goal of the research is to look at the goals of anonymity and the mental models people have. Anonymity does have a range of meanings to different people.
Maschio Fernando
Title: Privacy vs Persuasion: The consequences of LLM design
LLMs are designed to be very engaging to use. They exhibit emotion, nonjudgement replies. One of the top use cases for LLMs is companionship.
How do conversation cues by LLMs impact users. Sycophancy can overly impact people by agreeing with them. Inter-entity validation may impact what they feel comfortable disclosing.
Agreeableness vs sycophancy in LLM chatbots
- Agreeableness - helpful, genuine, cooperativeness, warmth
- Sycophancy - extreme opinion alignment, flattery, excessive validation
Sycophancy has been shown to increase users trust. Shift decisions toward suboptinal choices.
Study was run using US Social Security Knowledge. Participants completed a Social Security knowledge questions, and then were asked sensitive financial questions. A chatbot was used to interview participants.
- Survey - no chatbot
- Neutral chatbot
- Sycophant chatbot
- Disagreement chatbot
Participant using sycophant chatbot: “The chatbot made me feel more confident in my responses”. Participants assigned to any chatbot disclosed less information than in the survey condition.
Tesary Lin (Boston University)
Title :Regulating Consent Choice Architecture: A consumer welfare perspective
Two approaches to regulating consent choice architecture:
- Targeted restrictions - ban certain types. For example banning “pre-ticked boxes” (GDPR - Recital 32). Or “It shal be as easy to withdraw as to give consent” (GDPR Article 7(3). )
- Problem is that companies can A/B test and find an alternative approach that will work just as well. Develop new dark patterns.
- Reducsing exposure Opportunities
- “A business shal not develop or maintain a browser that does not include functionality … that enables the browser to send an opt-out preference signal.” (California - opt me out act, 2025)
- Reduces the exposure to consumers - if consent banners become rare consumers will pay attention to them more
- But there is no free lunch because if we do browser-level consent, we loose grainularity.
Research Question: site-specific consent vs Browser level consent
Leverage a browser-enabled plugin.
- 7 day experiment
- Choice architecture tested
- Deliberate obstruction (hiding “reject all”)
- Reordering option s
- Greying out options
Choice frictions such as hiding options reduce users opting out. Policies that target such frictions would have the best improvement.
Takeway:
- Choice friction matters
- Browser-level choice maximizes consumer welfare
Florian Schaub
Title: Layered, Overlapping, and Inconsistent
Most people do not read privacy policies: long, you cannot do anything anyway
In financial industry privacy policies are dictated by the GRAMM–LEACH–BLILEY ACT - these are shorter, more comparable, and you do have choices. But…. that is not the only notice banks offer: mobile notice, website notice, Californian notice.
Studied largest banks by asset value. Compared policies.
- GLBA notice, general, mobile CCPA, and ???
GLBA notices are nice and easy to auto extract. The other ones require lots of manual effort.
Findings
- Half of the banks had at least one policy beyond GLBA notice, some had 5
- The bigger the bank, the more words there are and the harder they are to read (Flesh Kinkade Score)
- Of banks that say in GLBA notice “we do not share for marketing purpose” but in other policies they are sharing for marketing purposes
- GLBA might also say that they are sharing, but other notices say they are not sharing
Takeaways
- GLBA has lost meanings because you also need to read all the other notices.
- These policies might not be legally inconsistent. GLBA only covers financial data. It may be that an app is tracking non-financial and sharing that. But that is confusing to end-users.
Christina Fong (Carnegie Mellon University)
Title: An experiment in hiring discrimination via online social networks
Interested in inter-personal decision making. For example: who should I hire, but I can only hire one person… so am I worried about not hiring at all or worried about hiring the wrong person.
Psychology has deep information about how we process new additional data in our brains. When we hear a name we pull on our own memory to build a more full mental understanding of who that person is, and that constructed mental understanding is then used in decision making.
Do US employers actually search candidates online?
- Does what they find impact their decisions
Study manipulated online social network profiles. Then applied for >4000 jobs and measured callbacks. This was a real world experiment.
Did see a strong reaction in certain states where the religion which was only disclosed on social media had an impact on who was ultimately given a callback.
Melissa Hathaway
Title: Privacy
What keeps me up at night?
Over the last 17 months we have had an unprecidented shift in Privacy in the US. The department of government efficiency run by a technology person: Elon Musk. All the data was accessed, data that was never meant to be co-mingled. We still do not know how many copies of that data still exist. The IRS gave access to all the tax refund. Treasury made an information sharing agreement with ICE to “enhance” enforcement. CBP bought access to ClearviewAI to get biometrics. Federal government is trying to get access to state voting records. Most of this requested data was not encrypted. Data was sent to Palantir who is “enhancing” it with social media knowledge. All of that is now being used as part of the surveliance state.
Violation of the Privacy Act of 1974.
Privacy in the age of AI
- Lawsuit against Perplexity - they have a privacy mode, they have an opt-out. They have an agreeable prompt, that is trying to be more agreeable and get more data. The terms and opt-out was not honored.
So what is privacy in the age of AI?
Is consent linked to a conversation. Consent for recording of conversations is different legally. Is chatbot consent more conversation like? or more Terms of Service like?
Are we back to “I’ve got a free service and I’m the comodity” but AI is for pay. So is it now “I’m paying and I’m still the commodity”.
Q&A
- For Florian - what level did you find that LLMs were helpful in summarizing Privacy Policies. Getting an AI to read a privacy policy for us sounds great? Is it possible?
- Answer: we didn’t use LLMs for interpretation. In other work we have found it to work so so. The challenge is that privacy policies are ambiguous by design. They are designed that way so that every time an engineer makes a change they do not break their own privacy policy.
- Privacy policies are useful for regulators, but not really for consumers
- The goal of the companies is for their model to be the single point of interaction for users. So interactions come in through the funnel of LLMs.
- We are moving more into a surveillance state.
- We worry about LLM providers gaining too much market power. Right now there is competition, but we worry that this will not last. If there is too much market power, that is bad for consumer privacy.
- Depends on if the AI is an agent, or if the AI a double agent.
- WeChat in China is already an economic model for a central point of market weight.
- Story: we think about consumer choices and then we think about policy. But there is a middle layer of the service provider. A few years ago searching for a consent provider. Most companies in this space are new. We were trying to get a system, but the issue was the cookie banner. We wanted consumers to have certain choices. I learned from the experience is the consent provider is trying to teach clients how to get consumers to agree to more tracking.
- Consent providers are not neutral parties. They represent the interests of the individual websites. Because the websites pay for them.
- Consent providers are fighting against browser-based consent. Because it would undermine their financial model.
- Mozilla review of the automotive policies turned up some fascinating things. Like how passengers are agreeing to give away their medical data by riding in a car. The research concluded that the above statement was likely caused by copy/paste from other policies.
- At no point in the purchase of an automobile are you ever told about the policies or walked thorugh them.
- Even worse if you get in an Uber
- AI can also change privacy for the better. There has been extensive research into automated reading of privacy policies (Usable Privacy Policy Project). Humans do not read the policies. AI is less accurate, but that is still better than not engaging at all due to being overwhelmed. Maybe we should be measuring regret rather than up-front understanding. How might AI be used to improve privacy for users?
- The policies are vague. There is only so much AI can do if the information is not there.
- But do we have local models that can do that? Are they the user’s agent or are they a double agent.
- Why is privacy strictly consumer. Because if they are stealing $4 a day of your time, $2 of that time is probably work time. So why don’t companies take employee privacy and employee data more seriously?
Session 4: Individual Security Behaviors
Speakers: Richard John, Norman Sadeh, Nathan Malkin, Kent Seamons, John D’Arcy, Rick Wash
Richard John (Georgetown University)
The Cognitive Mechanics of Normalcy ias in High Consequence Environments
Does research on cognitive modeling
Thinking about situations where military (or similar groups) have an incident and after the incident we worry “we should have been able to predict this”. But the incident does actually look like non-issues.
Normalcy Bias might be the cause.
SDT Decision Thresholds - there are two distribution of signals, one where we have an issue and one where we do not.
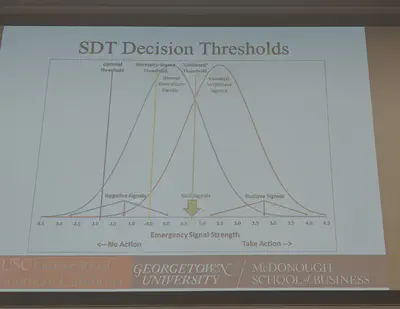
When we look at decision making more broadly. Its necessary to decide if a signal is positive, null, or a problem.
The penalty function is asymetric. It is far more expensive to send someone out to check on a detected signal than it is to decide it is not real. This feeds into Normalcy Bias.
Norman Sadeh (Carnegie Mellon University)
A large percentage of security incidents can be traced in some way or another to human error. Someone either doing the wrong thing, or failing to the right thing.
The other way is to let users ask questions. Users used to search online. Now GenAI is an option, but their accuracy is not the greatest. One of thie issues is that security is a secondary task, so there is no guarentee that people will act on advice. So we have been looking at how to best motivate people: nudging.
“Your Location has been Shared 5,398 Times!” this motivates users to look. But these are canned answers and they can be tested for efficacy. But with AI you don’t know what the question is going to be and similarly the answers will be dynamically generated.
- H. Almuhimedi, F. Schaub, N. Sadeh, I. Adjerid, A. Acquisti, J. Gluck, L.F. Cranor, Y. Agarwal, “Your Location has been Shared 5,398 Times!: A Field Study on Mobile App Privacy Nudging”, Conference on Human Factors in Computing Systems (CHI 2015), Apr 2015
Built Chrome plugins - what does it take to get people to act on advice being given to them? Started in the lab asking for people to give feedback.
Early work used Protection Motivation Theory (PMT) to help build prompts that are intended to be motivating.
Study with chat-style Chrome extension. Asked users to ask at least 2 questions a day, which they did and some asked more. Did a daily mini-survey at end of each day. Controled for PMT-style prompt or not.
- PMT did make a big difference.
- Participants were more likely to follow answers generated with prompt engineering
- Some participants kept using the tool after the study
There are many ways to improve the effectivenss of answers generated by LLMs.
Nathan Malkin (NJIT)
One way to improve usable security and privacy is to remove security decisions from users. Skeptical of security education. It is the opposite of automated security. The security decision is so hard that we have to teach them, and of course once we teach them they will never mess up in the future. Where is all this learning supposed to be happening? Do everyone take classes in it?
Actually it turns out that K-12 schools are teaching cybersecurity. Have been researching what teachers are teaching to kids:
- Most security-related instruction happening in computer science courses - almost always electives
- They are still learning from tech teachers, homeroom teachers. “Education” happening a range of ways from unstructured interactions all the way to capture the flag.
- Less common though than messaging like “don’t talk to strangers”.
Looked at Teaching Standards published by states - what teachers should be teaching at different grade levels.
- About a third are related to cybersecurity (ethics, biases, what is malware, digital citizenship, encryption)
- Standards don’t seem to be clear on who is being educated: everyone? future tech professionals?
What is it that schools should be teaching to students?
- Interviewed security experts.
- Experts like the teaching standards that exist.
- Education should emphasize a different kind of thinking.
Security as a habit
- Not so simple…
- So many stimuli - habits are repeated reactions to stimuli
- But what are the stimuli we want to condition in security? Stimuli are everywhere and anything can be a threat. Very hard for people to do.
Security as a mindset
- Suspiciousness - The role of human operators’ suspicion in the Detection of cyber attacks
- Curiosity
- How do we teach these? Suspiciousness and Curiosity are very hard to teach.
Kent Seamons (Brigham Young University)
Title: Deniability ois more than Protocol Feature
Secure Messaging Authentication Ceremonies are Broken - but most of the time these ceremonies succeed so users may see it as a waste of time.
What is Cryptographic Deniability?
- Millions of users now use tools that have cryptographic deniability - what is users understanding?
Looked at both what users think and what we are seeing in court cases. There needs to be in-app support, legal acceptance and societal acceptance. All three are needed or it does not work.
Found 228 court cases involving WhatsApp, a third had WhatsApp as major source of evidence. But 0 cases when cryptographic deniability was used in the argument.
Users were alarmed by deniability - they felt that only bad people would need this. Most expected non-repudiation from their chat tools. The need for deniability is dependent on lots of context like who is being chatted with or over what medium.
Users would trust more if there was a screenshot of a conversation, even more if someone pulled up their app and showed it to them.
So tried modifying Signal to allow users to edit messages sent by others. Gave uesrs an example of conflicting transcripts (phone 1 != phone 2). Seeing these edit ability in apps helped people understand deniability much better.
Idea: giving users a tool to let them try it out and experience security concepts. Would like to explore this idea more.
John D’Arcy (University of Deleware)
Title: An Idiographic Approach to Behavioral Cybersecurity Research
Time will tell the case for idiographic approach to behavioral Cybersecurity research
Deterance Theory - if you increase the costs of engaging in a behavior then in theory the behavior should reduce
Idiographic approach - person specific approach
Looked at a large number of papers looking at computing behavior - predicting behavior?
An idiographic approach allows researchers to consider a single user across time. Employees for example are not equally vulnerable at all points in time. (Have they had their coffee yet?) Provide distinct theoretical insights on behavioral data within a user.
Users often rationalize actions: “no real harm”, “I had no choice”.
This study looked over the course of a work week.
- Ego depletion - your ability to self-regulate are diminished over the course of the work week. So more self-rationalize may increase.
- Had people take surveys MWF.
- Measures Neutralization to compliance - as I neutralize more my compliance goes down. Neutralization becomes more influential later in the workweek.
- Outcome highlights that considering the impact of time is important in analysis.
Rick Wash (UW-Madison)
How people think about making security decisions.
What are some of the phylisophical aspects to decision making.
- We ask people to be careful and not click on dangerious or fraudulent links.
- We ask people to use specific technologies like two factor.
- If you see something say something
We make many requests of people to do security. Doing security requires the people on the ground helping.
- Some requests are reasonable: don’t post your SSN online
- Some are impossible: memorize a password so long/complex that a computer cannot guess it
We make requests all the time. Technology design is all about making requests of people. Policy design (organization policy) makes requests of people.
What are reasonable requests to make, and what are unreasonable. We normally talk about this in terms of usability. How hard is the request - how difficult/easy is it.
Usability is not a great framework for understanding security requests. It is a good start, but not enough on its own.
Why is it that we do security? Someone should be benifit from doing security to make it worth it for everyone to be involved in it. What do those benefits look like? In theory if employees are more security they can get more done. For example the recent Canvas attack means that teachers could not get grading done on time.
Users want to keep control over their things. Having control over those things is valuable, a security incident causes the loss of that control. Security also gives stability. It enables us to plan for the future. The ability to plan is also important for autonomy - for feeling like we have control over our own lives.
Connect the benefits of security back to the concepts of security requests. Reasonable security requests should provide benefits for the people who are fulfilling the requests. In cybersecurity we normally ask users to do tasks that should benefit from those actions through having security.
Started with a simple framework from bioethics. Think about how we train doctors: autonomy, minimize harm, and justice & and fairness. Starting to use this framework to think about how to think about requests. Usability does not handle autonomy and the fairness aspects. A command: “do this or get fired” is different from autonomy.
Requests like “don’t click on links” is unreasonable because of the restriction on autonomy.
Fairness is an interesting because it depends on who the request is being made of. Power relations.
Q&A
- To Kent: how much is the issue around putting users in the drivers seat to help them understand, or is it more around visibility.
- You only get the benefits of security if you know you have security.
- There are many different facets of security and in different contexts. Making things harder to give confidence is also possibly seen as manipulative.
- To Rick: Nothing to hide, nothing to fear. Justifications of security and how that relates to justifications of security requests.
- In the national security space we often talk about social contract theory to gain a collective benefit of national security. How does that map into the cybersecurity relm.
- There is this visibility thing and this social contract thing. Now we have PassKeys. Password managers are very transparent, you can see the random generated email. PassKeys are “better” than passwords - you cannot see it, you cannot modify it, but trust us that its safe. PassKeys have missed the visibility. We need to stop equating non-compliance with the user being wrong.
- PassKeys - is there anything we can do to make visible. This is a hard space to work in in terms of explaining what is happening.
- What it means to be transparent for people in this room is likely different from being transparent for an average person on the street.
- There is an imbalance in terms of signal interpretation. The costs of not sending out someone to check on a (potentially false) signal are born by the ship that may be in distress. How can we flip that computation.
- There are very few false negatives, many false positives. So the operator is always thinking about if it is a false positive. But there is serious negative outcomes in cases where a real signal is ignored. So it is less an incentivization issue. The costs of sending someone out to check is just more immediate and expensive.
- To Nathan - the schools have locked down devices. The schools are punting the problem to the parents. The parents are assuming that the school will handle. And the kids are doing whatever they want.
- Many of the behaviors they are responding to are happening outside of schools when they are not supervised.
- Thinking of cognitive depletion as an explanation of why secure behavior is not followed. But in some situations the secure vs insecure behavior have similar effort.
- Our perspective is that security is an add on to employee tasks. Most people do not think: “yipee! I get to do security.” There are possibly boundary conditions.
- To Rick: What are we giving away now that 30 years in the future will be considered sensitive.
- Phone numbers are like that. We used to publish them in phone books. Now it is how we access some apps.
- Hopefully deletion will become more of a thing.
- We have already talked about deepfakes. People may become more pretective of voice/video recordings.
- The future is very scary. Our ability identify people based on seemingly simple data is quite good.
Kami Vaniea
Associate Professor of Usable Privacy and Security
I research how people interact with cyber security and privacy technology.