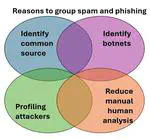
Clustering phishing and spam attackes into groups often called campaigns has been an ongoing research direction, but the work on it uses a supprisingly wide range of definitions of campaign as well as approaches to define groups. In this work we systemize prior work aiming to cluster or group phishing and spam emails using commonalities. Such commonalities can vary significantly. We looked at 23 research articles on grouping spam and phishing emails, focusing on two foundational aspects (definition of a group and use case) and four methodological aspects (dataset, input features, clustering or grouping algorithms, and evaluation strategies). We propose three definitions of `campaign’ representing how researchers approach the groupings: source-based, scam-based, and response-based. Furthermore, we discuss the various features and algorithms that have been utilized in relation to the goals of the researchers and highlight the key takeaways and recommendations for future work.